

SAMSON maintains all information about models, simulators, etc., in a data graph.
The SAMSON data graph contains everything directly or indirectly added by the user through SAMSON's user interface, SAMSON Extensions, etc. A data graph node has basic pre-defined data and functionalities to manage the data (models, apps, etc.).
All nodes in SAMSON's data graph, e.g. atoms (SBAtom), bonds (SBBond), etc., derive from SBDDataGraphNode. The figure below shows the document view, which is a view of SAMSON's data graph structure.
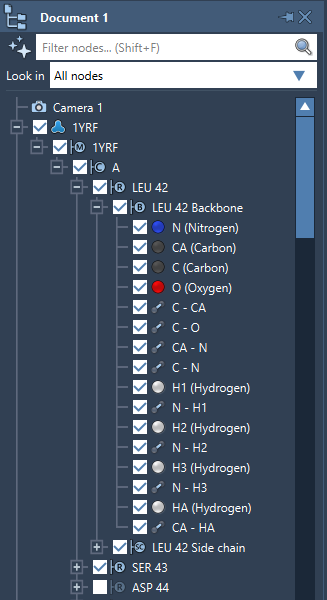
Topology
SAMSON's data graph is a directed graph, where each node has one and only one parent (with the exception of documents, which have no parent), and possibly some children. The parent of a node can never be directly set, but can be retrieved using the SBDDataGraphNode::getParent function. Children are managed using the SBDDataGraphNode::addChild and SBDDataGraphNode::removeChild functions, that are reimplemented in derived classes.
SAMSON Documents have a hierarchical structure:
- A document may contain all the node types, e.g.: folders, models, simulators, controllers, cameras, groups, paths, conformations, labels.
- A document folder may be used to arrange nodes and may contain different nodes such as other folders, models, simulators, controllers, labels, paths, conformations, etc.
Multiple documents may be opened simultaneously in SAMSON. See User guide: Documents for more information.
Node lifecycle
In SAMSON, a data graph node may go through four lifecycle stages:
- C++ object creation (e.g. with a
newoperator) - Node creation (using the create function)
- Node destruction (using the erase function)
- C++ object destruction (usually automatically, or forced with a call to
deleteReferenceTarget)
As reference targets, data graph nodes should not be destructed using the delete operator, because objects that are referencing them need to stop doing so before the node is deleted. Thus, when a node needs to be deleted (in the C++ sense), a SAMSON pointer must be used:
- See also
- Referencing
- Memory management
Node identity
Each node in the data graph has a type, which may be retrieved using the getType function. For example, the type returned by the SBAtom class, which derives from the SBDDataGraphNode class, is SBNode::Atom, while the type returned by the SBMStructuralModel class is SBNode::StructuralModel. The getTypeString function is a convenience function that may be used to obtain a type as a string.
Types may be used, for example, to rapidly search the data graph:
Each data graph node also has a unique index, that is managed internally by SAMSON. All indices are contiguous unsigned integers between 0 and n-1, where n is the number of data graph nodes. As a result, the node index is not permanent: when node i is deleted (and i is different from n-1), then node n-1 becomes node i. Node indices are used for example when picking objects in a viewport, by writing integers into the framebuffer instead of colors. The unique node index can be retrieved using getNodeIndex.
- See also
- SBDDataGraphNode
Flags
Each data graph node has four flags:
- The created flag indicates whether the node is created or not (see Node lifecycle)
- The visibility flag indicates whether the renderer should display the node in the viewport
- The highlighting indicates whether the renderer should highlight the node in the viewport
- The selection flag indicates whether the node is selected or not
These flags are accessed through functions of SBDDataGraphNode and, except for the highlighting flag which has temporary purposes, changing these flags' values is undoable. The getFlags function returns an unsigned int that combines the highlighting and selection flags.
- See also
- SBDDataGraphNode
Materials and color schemes
Each data graph node may have a material, which may affect its rendering in the viewport. Each material has a color scheme which may be modified and used to associate a color to a node or a spatial position. When a material is added to a node, it affects the node itself and all its descendants (unless they have a material themselves, which then has priority).
- See also
- SBDDataGraphNode
Node predicates
The SBDDataGraphNode class defines a series of node predicates, i.e. functors that may be used to e.g. collect nodes in the data graph. For example, the SBNode::IsType predicate may be used to collect nodes by type and the SBNode::IsSelected predicate may be used to collect all nodes that are selected (directly, because their selection flag is true, or because one of their ancestors is selected). Predicates may be combined through logical operations. For example, collecting selected atoms may be achieved with:
Please refer to Getting nodes for more information.
Node getters
The SBDDataGraphNode class also defines a series of node getters, i.e. functors that may be used to collect nodes in the data graph. For example, the SBNode::GetType getter may be used to retrieve the type of a node instead of through the getType function:
Node getters may be used to construct node predicates through comparison operators, so that collecting all atoms may also be achieved with:
since the statement SBNode::GetType() == SBNode::Atom constructs a node predicate that is passed to the getNodes function.
In general, node getters have the same name as the corresponding getter function, but the first letter of their name is capitalized, since they are classes. For example, just like the SBNode::GetType getter corresponds to the SBNode::getType function, the SBAtom::GetTemperatureFactor getter corresponds to the SBAtom::getTemperatureFactor function.
Node predicates and node getters may be used to collect nodes from potentially complex rules.
Please refer to the Getting nodes: Node getters for more information.
Serialization
Data graph nodes support serialization through the serialize and unserialize functions. Serialization is used in SAMSON to e.g. copy, paste, save, load, etc. data graph nodes. Please refer to Serialization in SAMSON for more information.
- See also
- SBDDataGraphNode